



Back to articles

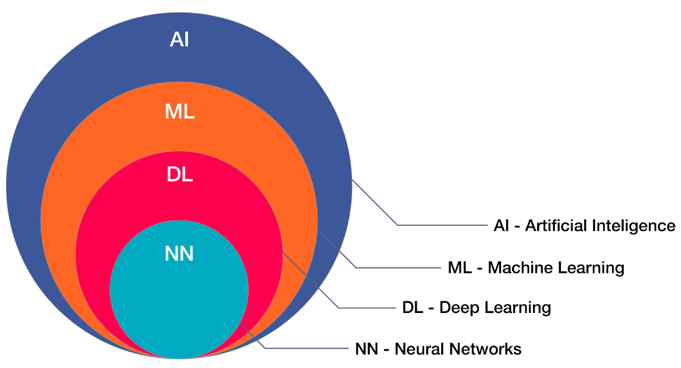
Artificial Intelligence (AI) and one of its subsets Machine Learning (ML) both represent a step change in human existence. We’re still wrangling with some of the ethical questions, but the potential benefits they offer are mind-boggling.
AI is a very wide topic, so here we’ll look in detail at ML and especially how it is seeping out of the cloud and towards the network’s edge.
What is Machine Learning?
‘Can machines think?’ – This question led the great Alan Turing to develop the ‘Turing test’ which has remained the benchmark to answer that very question. If machines can learn, then QED are they thinking? Well, that is still the subject of much debate about what defines ‘thinking’. Machines need a basis to start from, but they are learning autonomously and developing greater powers of comprehension as time goes on.
What really triggered the explosion in ML was the arrival of almost unlimited capacity and access in Cloud Computing and Big Data. Back-end systems can hoover up data and then run algorithms on cloud servers. From there, we can gain insights and make decisions. So, ML gathers data, processes it based on algorithms and training sets in the cloud, and takes action, with new learning paths created all along the process. Human intervention isn't absolutely necessary.
ML has four categories of operation: Supervised, unsupervised, semi-supervised, and reinforcement.
Supervised learning
Supervised learning use labelled datasets with features. These are then given to the learning algorithm during the training process where it will work out the relationship between the selected features and the labels. The learning outcome will then be used to classify new un-labelled data.
Unsupervised learning
Unsupervised learning happens when we often don’t know what the correct answer will be, and therefore the dataset is unlabelled. In such scenarios, it is expected to discover patterns that suggest natural groupings in the data by itself. The answer isn’t obvious. Moreover, there could be many combinations of the correct answer dependent on what variables are factored in.
Semi-supervised learning
What can we do with a large dataset that is only partially labelled? You either go through the process of labelling the rest of the data or you can try deploying a semi-supervised learning algorithm. Many real world machine learning problems fall into this category as it’s generally too expensive and time consuming to label your whole dataset for a fully supervised learning approach. On the other hand, an unsupervised learning approach may be unnecessary. Combining the two learning methods, therefore, should in theory give you the best of both worlds. Research has shown that the use of both labelled and unlabeled data actually offers the best long term results for learning.
Reinforcement
Reinforcement learning is the most sophisticated approach, and holds the closest resemblance to how humans actually learn. This sophisticated style of learning is inspired by game theory and behavioural psychology.
This method of learning usually involves an agent, the machine that is making the action, and an interpreter. The agent will be exposed to an environment where it will execute an action and then the interpreter will either reward or punish the agent dependent on the success of that action.
The goal for the agent is to find the best way to maximize the rewards by iteratively interacting with the environment in different ways. The only thing that the data scientist will provide in this type of learning is a method for the agent to quantify its performance.
This approach is already being used by many companies developing robotics and self driving vehicles. However, it’s usually deployed alongside other learning techniques such as supervised learning, creating an ensemble learning model. This is because it becomes difficult to apply reinforced learning to scenarios where the environment, actions and rules are variable.
Data grouping and classification
Data acquired needs to be classified into associated objects. Binomial classification is where the data will fall into one of two categories e.g ‘in temperature range’ and ‘out of temperature range’. Multi-class classification allows for multiple classifications e.g for a temperature classification it may read as: ‘in range’, ‘shut-down high’, ‘critical high’, ‘high alert’, ‘low alert’, critical low’, shutdown low’.
Anomaly detection is a type of single-class classification algorithm where the only goal is to find outliers in your dataset or unusual objects that appear outside of the normal distribution. This can be used in events such as strange transients in malfunctioning equipment.
Learning models
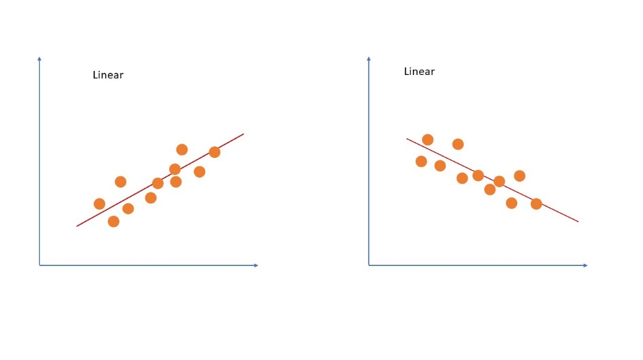
Linear regression
This technique has long been the staple of statisticians and Data Science and statistics bear considerable similarities in range of areas. Linear regression has also been applied to machine learning, as a standard method for showcasing relationships between a dependent variable and independent variable when the independent variable changes. Method of Learning: Supervised
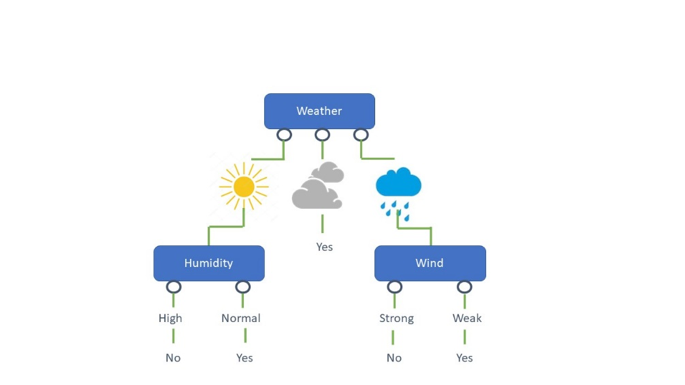
Decision trees
This type of algorithm has high interpretability and handles outliers and missing observations well. It is possible to have multiple decision trees working together to create a model known as ensemble trees. Ensemble trees can increase prediction and accuracy, whilst decreasing overfitting to some extent. Method of Learning: Supervised
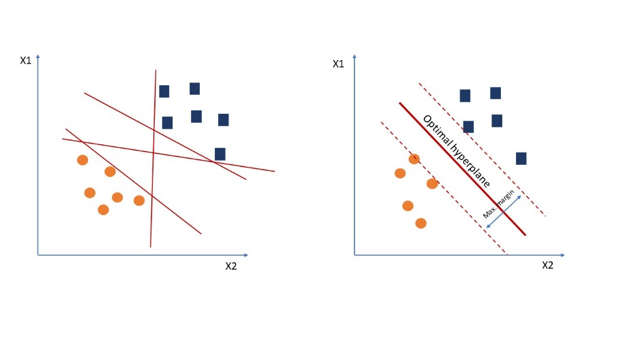
Support Vector Machines
Typically used for classification, but can also be turned into a regression algorithm, is Support Vector Machines (SVM). SVM can bring greater accuracy when it comes to classification problems by finding the optimal hyperplane, a division between the different data classes. To find the optimal hyperplane, the algorithm will draw multiple hyperplanes between the classes. Then, the algorithm will calculate the distance from the hyperplane to the closest vector points, commonly referred to as the margins. It’ll then choose to use the hyperplane which produces the greatest margin; the optimal hyperplane. Finally, it’ll utilize the optimal hyperplane in the classification process. Method of Learning: Supervised
K-Means clustering
K-Means clustering is used for finding similarities between data points and categorizing them into a number of different groups, K being the number of groups. Method of Learning: Unsupervised
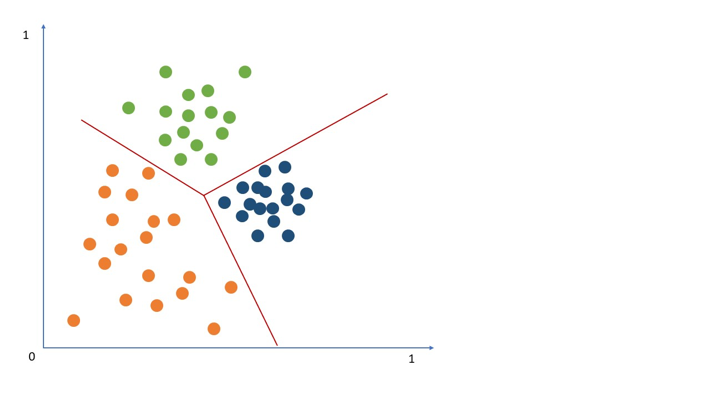
Hierarchical clustering
Hierarchical clustering creates a known number of overlapping clusters of different sizes along a hierarchical tree to form a classification system. This type of clustering can be achieved through various methods with the most common methods being agglomerative and divisive. The splitting process is repeated until the desired number of clusters is achieved. Method of Learning: Unsupervised
Neural networks
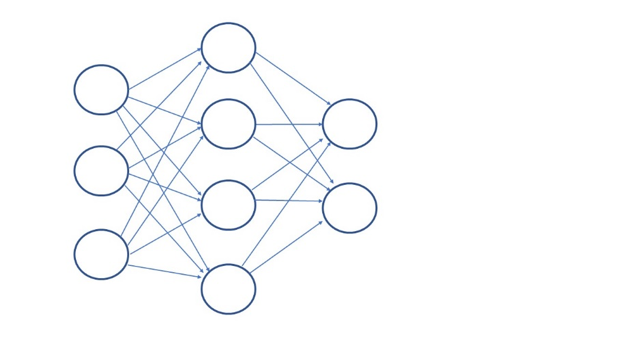
Neural networks are highly associated with robotics and neuroscience which naturally makes it the most exciting algorithm to explore. Neural networks, specifically artificial neural networks, consists of three layers; an input layer, an output layer and one or many hidden layers which are used to detect patterns in the data. It does this by assigning a weight to a neuron inside the hidden layer each time it processes a set of data. Method of Learning: Unsupervised
Taking Machine Learning out to the Edge
So now we have a little foundation on what ML actually is, what does that have to do with microcontrollers (MCUs) sitting in small embedded units in billions of products everywhere?
Well as the science of ML develops at lightning speed, so does its improvements in efficiency and tuned elements of ML fit for certain use cases. What once had to be done in the cloud, now has possibilities on MCUs that have for example a 1MB of flash and maybe 256kB RAM, such as the nRF52840 SoC from Nordic. No-one is saying this is a sinch to do in such constrained devices but it has been proven doable and wireless embedded SoCs at their top end just get more capable and the ML tools and algorithms become more applicable to such platforms. There are limitations of course, a device such as the nRF52840 is never going to compete with the sheer horsepower of a cloud based system. But what it can do is perform real-time, localized, application-specific machine learning without a cloud connection. Of course it can be used in conjunction with a cloud based system such as Matillion or many others to offer a hybrid ML approach that has myriad benefits.
ML Tools for embedded Cortex-M MCUs
There are a few tools out there today that enable the creation of learning sets for ML. Tensorflow is probably the best known together with its associated Tensorflow Lite. Developed at Google, it is an open source framework of libraries designed for ML. It is used by Google for much of their own AI purposes and is powerful enough for image recognition. The workflow follows a number of stages from building your model and training set using python together with the libraries. Tensorflow will then generate C++ code for implementation on a device or system. Other ML libraries are available from Apache MXNET, Microsoft CNTK and Pytorch.
Current developments and what next?
As of today, this is still a cutting-edge area of development with a lot of road ahead. But I think it’s a given we are going to see ML appear in a huge amount of embedded systems in the coming years, some quite perfunctory, some very complex. Voice and speech recognition applications clearly hold some appeal, as do audio recognition in machines where perhaps bearings or motors are approaching end of life and need replacement.
Just recently at this year’s Google IO event, Arm and Google announced a partnership on ML with their Tensorflow Lite and μTensor projects which will merge under the Tensorflow Lite Micro Project. There is an open source project using ML for Key Word Search (KWS) at Arm mbed that may be of interest to check out also here.
This is a story that has many more chapters to go, and we’ll for sure be telling you more about ML on Cortex-M and Nordic devices in the future.
